Event Tracking, czyli jak znaleźć igłę w stogu siana

Systemy zbudowane na bazie Apache Kafka korzystają na ogół z więcej niż jednego topika. Często też eventy w ramach pojedynczego procesu pokonują drogę pomiędzy różnymi topikami - w niektórych przypadkach ogranicza się to jedynie do przepływu pomiędzy topikami w niezmienionej formie, ale równie często rekordy na kolejnych topikach ulegają modyfikacji, np. dodawane są dane, które będą potrzebne w kolejnych krokach procesu. Event tracking pozwala na prześledzenie oraz wizualizację drogi danego eventu, czy też procesu, przez topiki na Kafce.
Weźmy za przykład system do wysyłania notyfikacji do użytkowników. Zanim dane powiadomienie będzie gotowe do wysyłki, potencjalnie będzie musiało przejść przez kilka topików, gdzie uzupełnione zostaną np. treść notyfikacji, czy kanał, którym powiadomienie zostanie przesłane.
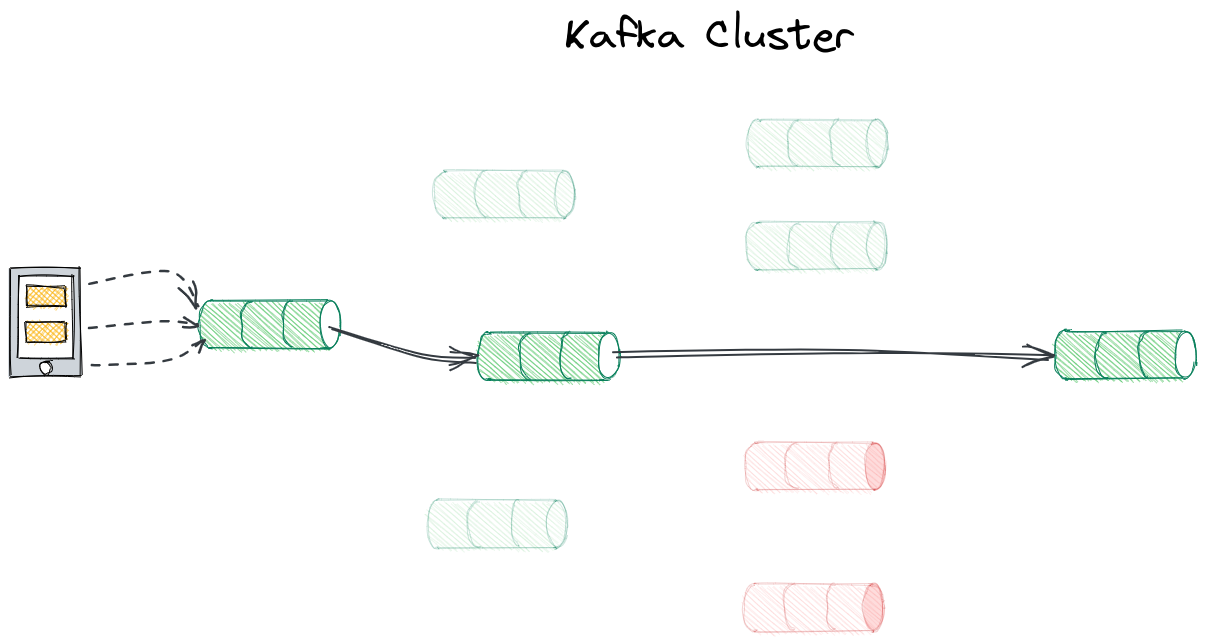 Przykładowy przepływ na Kafce
Przykładowy przepływ na Kafce
Jak wobec tego namierzyć drogę konkretnego procesu pośród milionów innych?
Gdzieś już to widziałem
W istocie, problem nie jest nowy i sięga co najmniej mikroserwisów. Jeśli w obsługę danego żądania HTTP zaangażowany jest więcej niż jeden mikroserwis, to potrzebujemy łatwego sposobu na prześledzenie logów związanych z obsługą tego żądania, niezależnie od tego, ile mikroserwisów w tym procesie uczestniczyło. Rozwiązanie tego problemu jest dobrze znane - kiedy żądanie pojawia się w systemie, np. kiedy trafia na API Gateway, wystarczy wygenerować losowy ciąg znaków, umieścić go w nagłówku HTTP, a następnie zadbać o przekazywanie tego nagłówka pomiędzy mikroserwisami, oraz wstrzyknięcie jego wartości do kontekstu logowania (MDC).
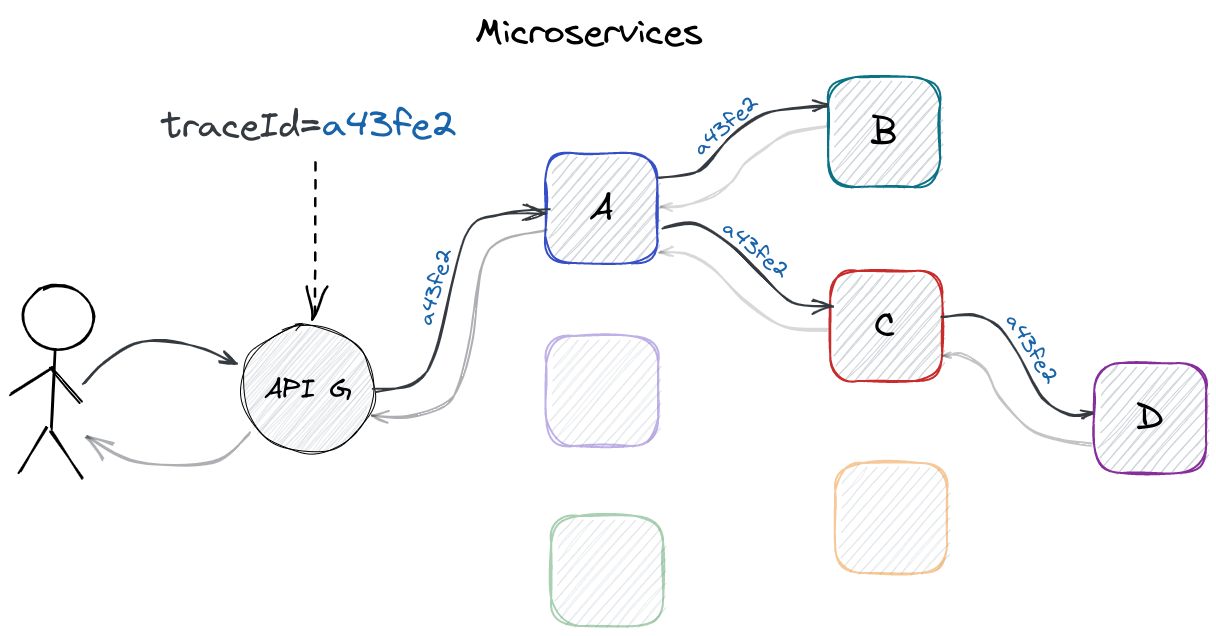 Śledzenie logów pomiędzy mikroserwisami
Śledzenie logów pomiędzy mikroserwisami
Dzięki temu, wszystkie logi związane z danym żądaniem będą powiązane wygenerowanym na początku identyfikatorem. Wystarczy wyszukać ten identyfikator w jednym z popularnych agregatorów logów, np. Splunk (zakładając oczywiście, że tego rodzaju narzędzie jest dostępne) i w rezultacie otrzymamy logi powiązane z szukanym żądaniem.
Ale co to ma wspólnego z Kafką?
Nagłówki na ratunek
Okazuje się, że doświadczenia z korelacji logów ze świata mikroserwisów możemy wykorzystać do event trackingu na Kafce. Z rekordami na Kafce, podobnie jak z wiadomościami HTTP, mogą być związane nagłówki, a więc metadane w postaci klucz-wartość.
Wykorzystując znany z mikroserwisów wzorzec, kiedy rekord pojawia się pierwszy raz w systemie, generujemy unikalny identyfikator oraz umieszczamy go w nagłówku. Następnie, analogicznie jak w przypadku mikroserwisów, kiedy event wędruje z jednego topika na inny, przekazujemy również powiązany z nim nagłówek korelacji. Idealnie, jeśli wartość tego nagłówka wstrzykujemy również do kontekstu logowania.
 Przekazywanie nagłówka pomiędzy topikami na Kafce
Przekazywanie nagłówka pomiędzy topikami na Kafce
Nie da się jednak nie zauważyć, że samo przekazywanie nagłówków pomiędzy topikami nie stanowi nawet połowy sukcesu. Prawdziwy problem leży w znalezieniu rekordów z tą konkretną wartością nagłówka pośród setek topików i miliardów rekordów.
Jak więc się za to zabrać? Trzeba zacząć od zadania sobie trzech pytań:
- Co? - czego tak naprawdę szukamy? Jakich nagłówków, z jakimi wartościami?
- Gdzie? - które topiki weźmiemy pod uwagę? przeszukiwanie wszystkich topików często będzie nadmiarowe, na ogół można ograniczyć się jedynie do tych związanych z pewną funkcjonalnością lub przepływem.
- Kiedy? - w przypadku kiedy na Kafce znajdują się miliardy rekordów, przeszukanie ich wszystkich zajęłoby wieki. W wielu jednak przypadkach procesy potrzebują kilku sekund lub maksymalnie kilku minut aby w pełni przejść przez Kafkę, co oznacza, że na ogół można zawęzić zakres wyszukiwania do 5, 15 minut lub np. godziny.
Co oczywiste, im mniejszy zakres poszukiwań, tym sprawniej ono pójdzie.
Jak zatem wziąć te trzy pytania i faktycznie prześledzić drogę procesu przez Kafkę? Out of the box, nie istnieją na Kafce mechanizmy, które pozwoliłby to prosto zrealizować.
Event Tracking w praktyce
Tak się jednak składa, że stworzone przez nas narzędzie, Kouncil, oferuje dokładnie taką funkcjonalność, rozszerzoną o dodatkowe opcje oraz optymalizacje. Zaglądając do zakładki Track znajdziemy filtry pozwalające wprost odpowiedzieć na powyższe trzy pytania.
- Po pierwsze, możemy określić jaki nagłówek z jaką zawartością jest dla nas interesujący. Możemy też wskazać sposób matchowania szukanej wartości nagłówka z faktyczną - nie musi to być dopasowanie 1 do 1. Do wyboru są takie operatory jak równa się, nie równa się, zawiera się, nie zawiera się, a nawet wyrażenia regularne.
- Po drugie, istnieje możliwość określenia zbioru przeszukiwanych topików - w przypadku, kiedy na klastrze znajdują się setki lub tysiące topików nie ma potrzeby ręcznie wyszukiwać ich na liście - komponent wyboru topika obsługuje filtrowanie.
- Po trzecie, mamy możliwość podania przedziału czasowego, który nas interesuje.
 Filtry zakładki Track
Filtry zakładki Track
Jednak każdorazowe wypełnianie tych pól ręcznie w końcu okaże się być co najmniej niewygodne.
Wróćmy więc do przykładu wysyłki powiadomień z początku tego artykułu. Przyjmijmy, że istnieją na klastrze topiki odpowiedzialne za przetwarzanie wysyłki powiadomień: notification-input, gdzie powiadomienia zaczynają swoje życie, oraz inne, przez które eventy przepływają w zależności od przypadku użycia. Tymi topikami mogą być notification-content, -channel, -template, -delivery itp., na których eventy mogą być uzupełniane o potrzebne dane. Na przykład na topic notification-channel wpadną eventy, dla których trzeba wyznaczyć kanał powiadomienia.
Zajrzyjmy do topika notification-input:
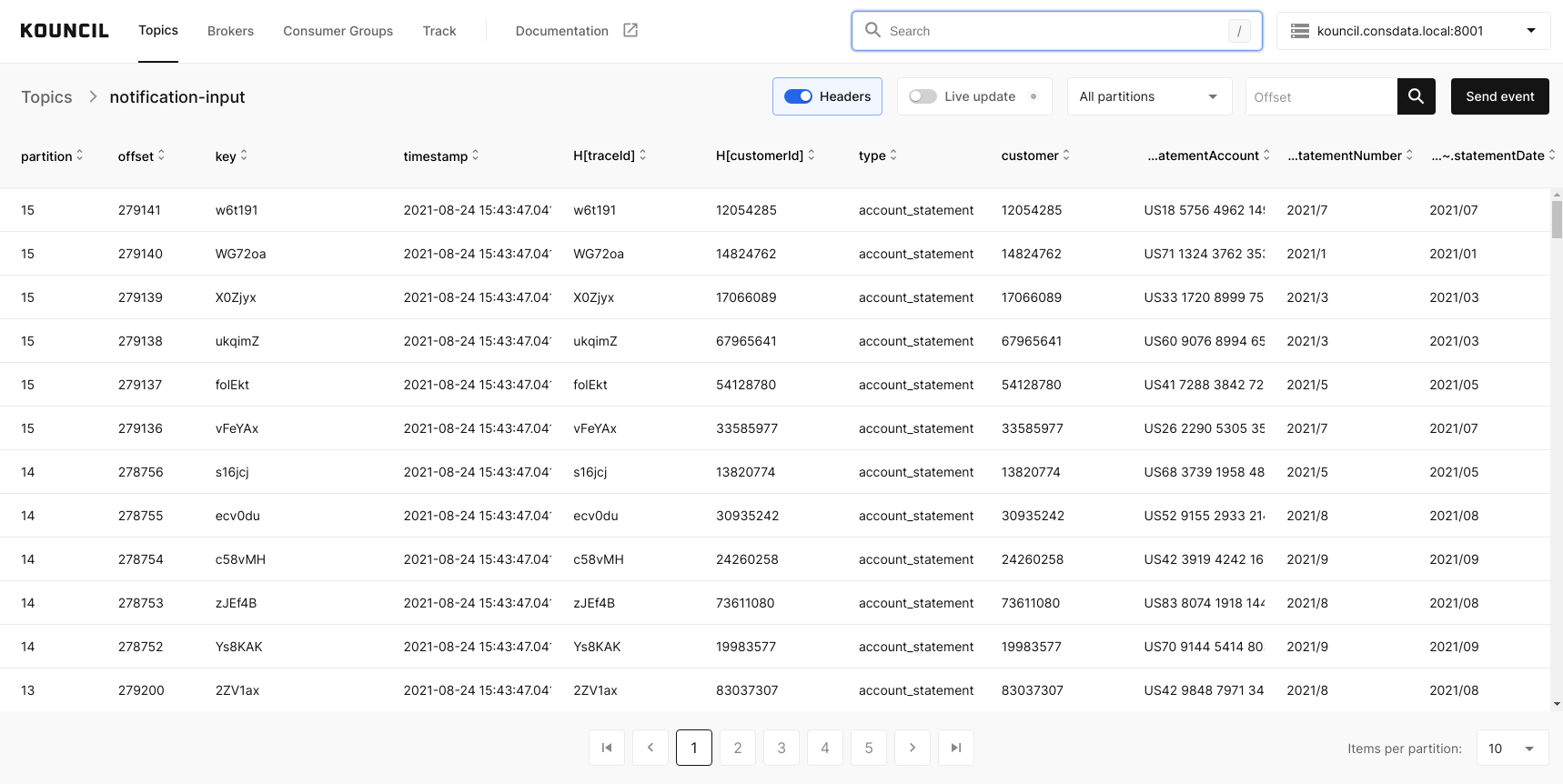 Topic notification-input
Topic notification-input
Załóżmy, że chcemy prześledzić drogę rekordu o kluczu vFeYAx. Wystarczy, że klikniemy w rekord, aby podejrzeć jego szczegóły, a następnie na interesujący nas nagłówek.
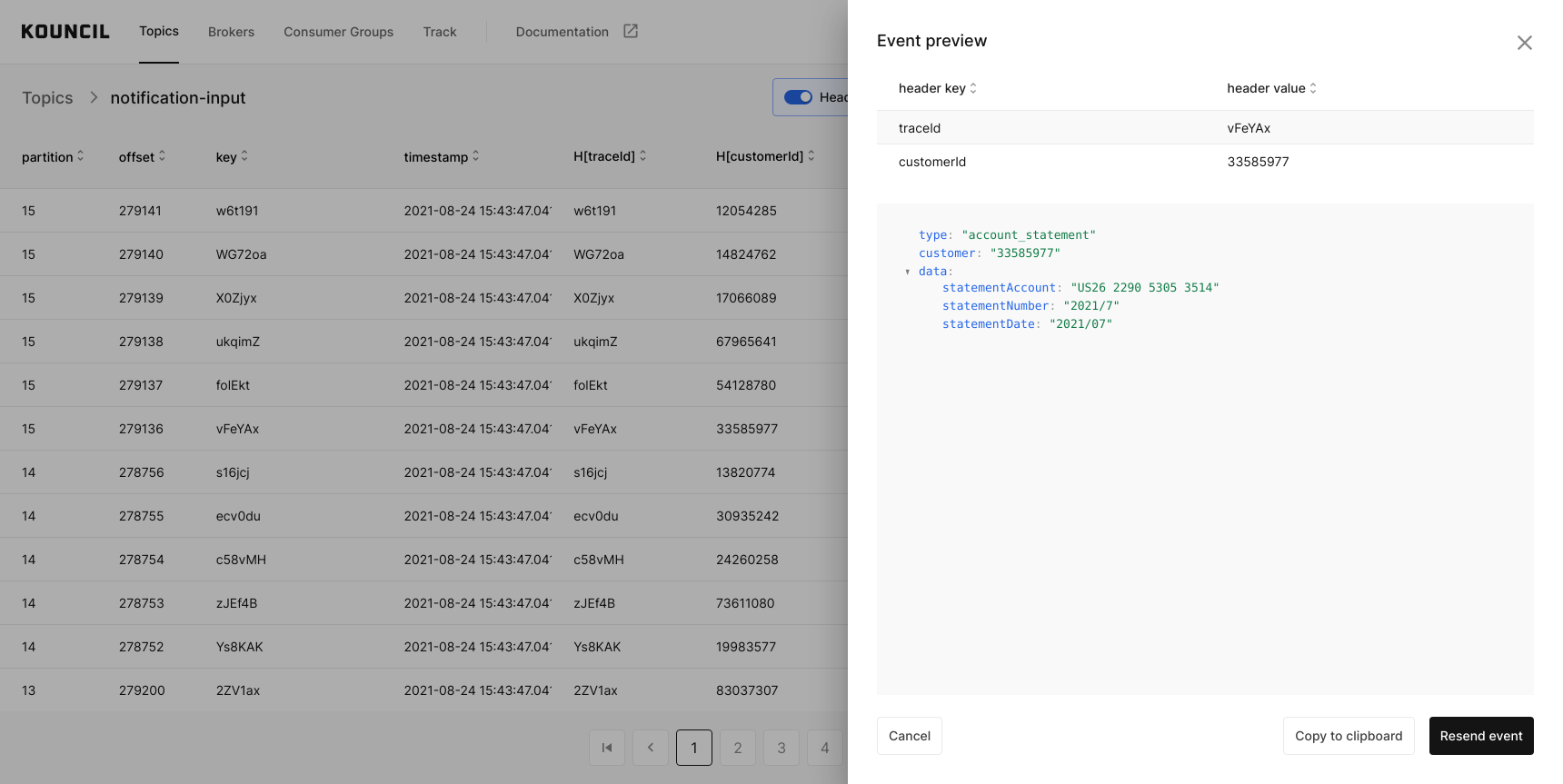 Wybór nagłówka
Wybór nagłówka
Zostaniemy automatycznie przeniesieni na zakładkę Event Trackingu, gdzie pola filtra będą już za nas wypełnione na podstawie wybranego rekordu! Jedyne co musimy zrobić, to dodać interesujące nas topiki, gdyż domyślnie wybrany będzie jedynie ten, na którym znajduje się event, którego drogę chcemy prześledzić.
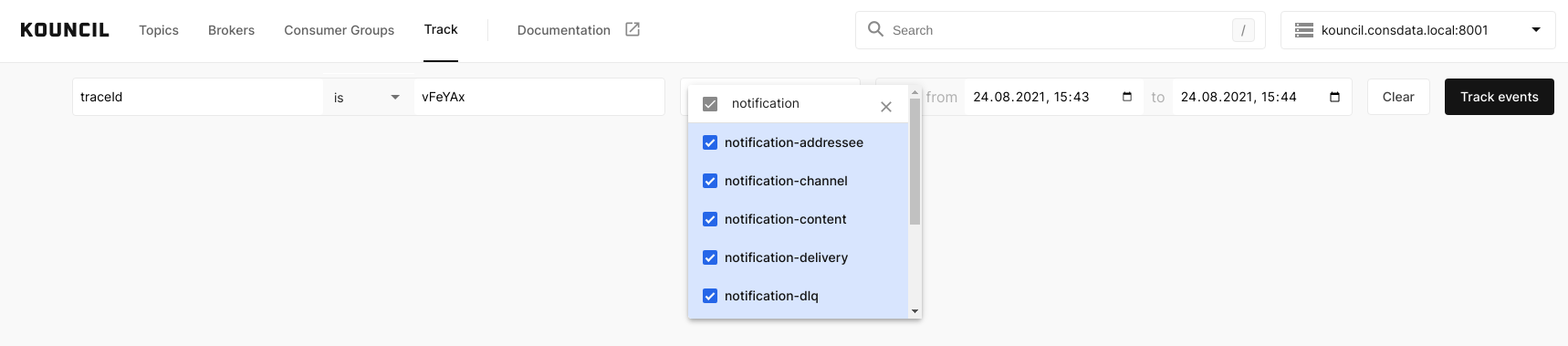 Automatycznie wypełniony filtr Event Trackingu
Automatycznie wypełniony filtr Event Trackingu
Teraz pozostało nam już tylko kliknąć Track events i obserwować jak w czasie rzeczywistym Kouncil odnajduje rekordy o podanym nagłówku. Sortując wyniki po czasie widzimy nie tylko kiedy oraz przez jakie topiki przeszedł dany proces, ale możemy też podejrzeć rekord na każdym etapie procesu.
![]() Wynik Event Trackingu
Wynik Event Trackingu
Taki sposób analizy przepływu procesów na Kafce pozwala zaoszczędzić sporo czasu, zwłaszcza w bardziej zawiłych procesach, kiedy rekordy mogą powtórnie trafić na topic, na którym znajdowały się wcześniej lub podczas analizy błędnych sytuacji, kiedy proces mógł trafić na topiki służące do obsługi błędów. Wyszukanie analogicznych informacji w logach aplikacji, choć możliwe, z reguły okazuje się być bardziej czasochłonne, szczególnie, jeśli konsumentami danego procesu są moduły należące do różnych systemów i nie istnieje prosta możliwość zbiorczego przeszukania ich logów.
Co ważne, Event Tracking możemy zacząć od dowolnego miejsca w procesie - może to być jego początek, tak jak w przypadku topika notification-input, jednak nic nie stało na przeszkodzie, żeby analizę rozpocząć od samego końca przepływu - topika notification-status - efekt byłby dokładnie ten sam!
Kouncil
Kouncil jest darmowy, a jego źródła wraz z instrukcją uruchomienia można znaleźć na naszym githubie. Proces jego uruchomienia jest trywialny i sprowadza się do pojedynczej komendy docker run, w ramach której trzeba jedynie wskazać namiar na którykolwiek z węzłów klastra Kafki. Jedyne czego Kouncil wymaga do obsługi Event Trackingu to zapewnienie istnienia nagłówków w wiadomościach, a resztę, związaną z przeszukiwaniem topików, bierze już na siebie.